Redis主从复制
一、简介
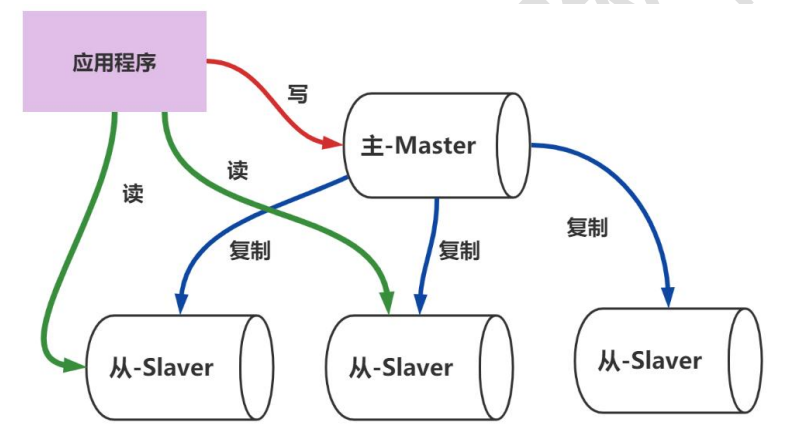
Master【主】:以写为主
Slaver【从】:以读为主
主机数据更新后会自动同步到从机,好处:
- 读写分离, 提升效率
- 负载均衡
- 容灾快速恢复,如果某个 slaver , 不能正常工作, 可以切换到另一个 slaver
- 高可用(集群)基石︰除了上述作用以外,主从复制还是哨兵和集群能够实施的基础
要求:一 主多从, 不能有多个 Master( 如果有多个主服务器 Master, 那么 slaver 不能确定和哪个 Master 进行同步, 出现数据紊乱)
二、主从搭建
本文在一台Linux服务器上通过三个不同的端口来模拟三个Redis服务的一主二从结构
1、创建三个配置文件
公用配置文件/zqlredis/redis.conf
#修改下面两个选项
daemonize yes
#只使用rdb备份
appendonly no
三个配置文件 redis6379.conf ,redis6380.conf, redis6381.conf
include /zqlredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
#其他两个文件依此修改
2、启动三个Redis服务

3、配置主从
将 6380 和 6381 配置成 slaver, 6379 作为主机Master
在Slave的Redis客户端执行以下命令
slaveof 127.0.0.1 6379
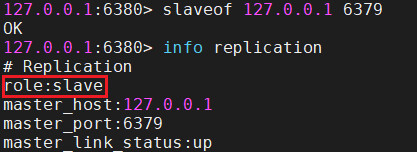
现在6380,6381端口的角色已经变成了slave,master_port为6379
三、主从复制原理
Slave 启动成功连接到 master 后会发送一个 sync 命令
Master 接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后, master 将传送整个数据文件到 slave,以完成一次完全同步,slave 服务在接收到数据库文件数据后,将其存盘并加载到内存中, 即
Master 数据变化了, 会将新的收集到的修改命令依次传给 slave, 完成同步, 即
只要是重新连接 master,一次完全同步(全量复制)将被自动执行
四、多种模式
1、一主二仆
- 如果从服务器 down 了, 重新启动, 仍然可以获取 Master 的最新数据
- 如果主服务器 down 了, 从服务器并不会抢占为主服务器, 当主服务器恢复后,从服务器仍然指向原来的服务器
2、薪火相传
- 上一个 Slave 可以是下一个 Slave 的 Master,Slave 同样可以接收其他 Slaves 的连接和同步请求,那么该 Slave 作为了链条中下一个的 Master, 可以有效减轻 Master 的写压力,去中心化降低风险
- 风险:一旦某个 slave 宕机,后面的 slave 都没法同步
- 主机宕机之后,从机还是从机,无法写数据了
3、反客为主
当一个 master 宕机后, 指向 Master 的 slave 可以升为 master, 其 后面的 slave 不用做任何修改
升级Master方法:在选定的从服务器上执行下列指令
slaveof no one
4、哨兵模式(sentinel)
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
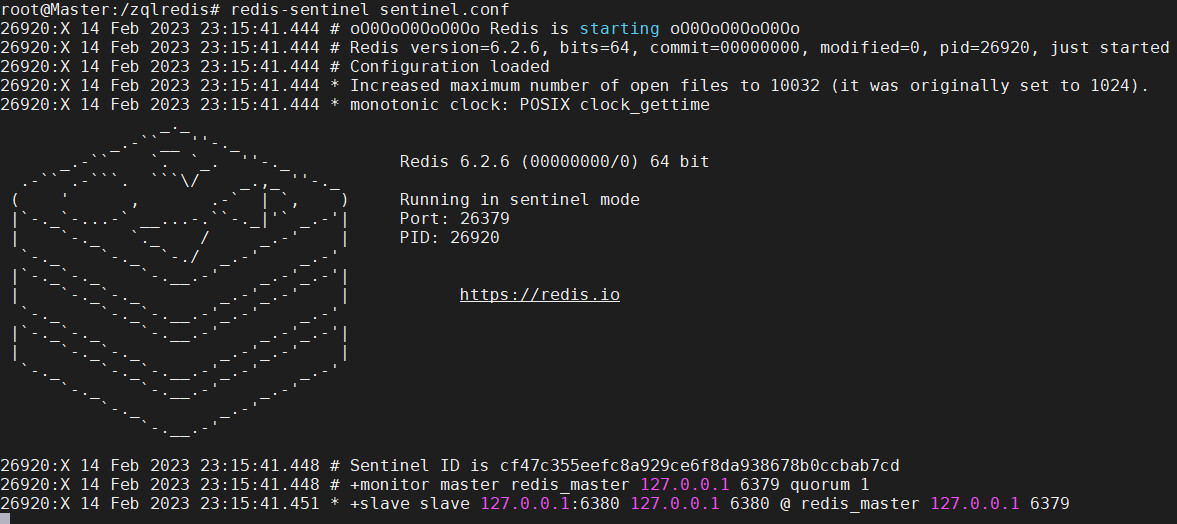
在一主二仆模式下,创建/zqlredis/sentinel.conf
sentinel monitor redis_master 127.0.0.1 6379 1
#redis_master 为监控对象起的服务器名称
#末尾的1表示只要有1个哨兵同意迁移就可以切换
启动哨兵:redis-sentinel sentinel.conf
哨兵如何在从机中, 推选新的 Master 主机, 选择的条件依次为:
- 优先级在 redis.conf 中默认:replica-priority 100,值越小优先级越高
- 偏移量是指获得原主机数据的量, 数据量最全的优先级高
- 每个 redis 实例启动后都会随机生成一个 40 位的 runid, 值越小优先级越高
五、集群
1、去中心化集群
redis3.0 提供解决方案-无中心化集群配置
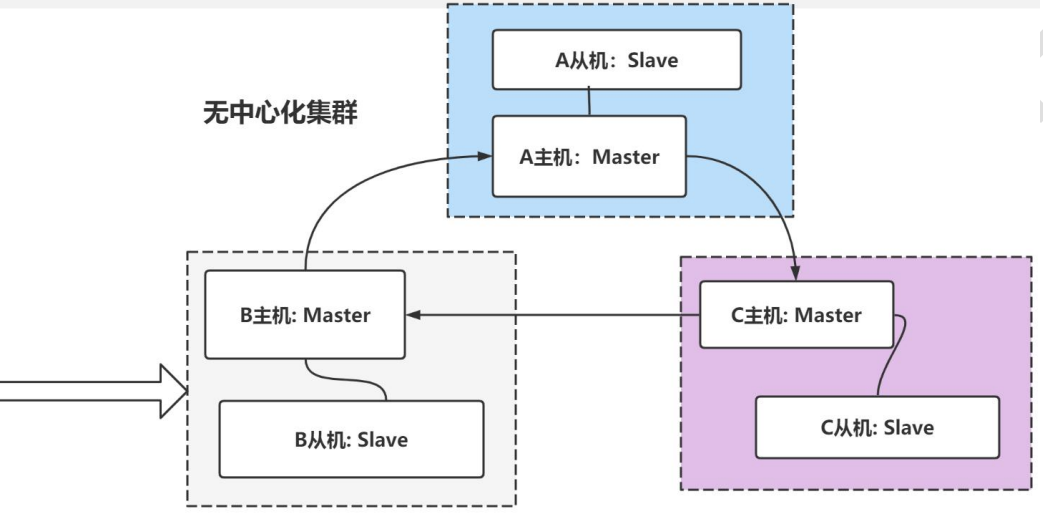
各个 Redis 服务仍然采用主从结构
各个 Redis 服务是连通的, 任何一台服务器, 都可以作为请求入口
各个 Redis 服务器因为是连通的, 可以进行请求转发
这种方式, 就是无中心化集群配置, 可以看到,只需要 6 台服务器即可搞定
Redis哈希槽:
一个 redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个。集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每一个节点负责处理一部分哈希槽。
2、创建集群
- 通过端口模拟6个Redis服务器搭建集群
配置文件目录如下:
其中 redis6379.conf 内容如下:
include /zqlredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
#rdb文件不能指定路径
dbfilename dump6379.rdb
#打开集群模式
cluster-enabled yes
#设置结点配置文件名
cluster-config-file /zqlredis/nodes-6379.conf
#设置结点失联时间(毫秒),失联超时后将自动进行主从切换
cluster-node-timeout 15000
其他配置文件依此类推
- 启动6个Redis服务

发现结点配置文件也成功生成了:
- 将6个结点合成一个集群
【合成集群的命令需要Ruby的环境,Redis6版本以上已经安装了】
redis-cli --cluster create --cluster-replicas 1 192.168.50.132:6379 192.168.50.132:6380 192.168.50.132:6381 192.168.50.132:6389 192.168.50.132:6390 192.168.50.132:6391
注意事项:
- 此处不要用 127.0.0.1, 要用真实 IP 地址
- replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组
- 搭建集群如果没有成功, 把 sentinel 进程 kill 掉重新试一下
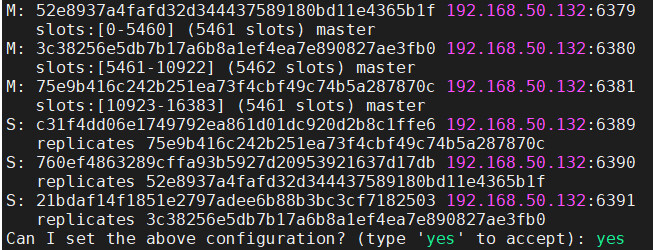
M代表主机,S代表从机,S后面的序列号可以判断出其从属关系:
| 主 | 从 |
|---|---|
| 6379 | 6390 |
| 6380 | 6391 |
| 6381 | 6389 |
3、集群使用
注意:一个集群至少要有三个主节点
#集群方式登录
redis-cli -c -p 6379
#查看集群信息,主从对应关系
127.0.0.1:6379> cluster nodes

哈希槽solts
一个 Redis 集群包含 16384 个插槽(hash slot),编号从 0-16383, Reids 中的每个键都属于这 16384 个插槽的其中一个
如何在集群中录入值?
通过redis-cli -c -p 6379登录后,可以实现自动重定向

不在一个 slot 下的键值,是不能使用 mget,mset 等多键操作

可以通过{}来定义组的概念,从而使 key 中{}内相同内容的键值对放到一个 slot

查询集群中的值
- 指令: CLUSTER KEYSLOT [key] 返回 key 对应的 slot 值
- 指令: CLUSTER COUNTKEYSINSLOT [slot] 返回 slot 有多少个 key
- 指令: CLUSTER GETKEYSINSLOT [slot] [count] 返回 count 个 slot 槽中的键
4、集群故障恢复
如果主节点下线, 从节点会自动升为主节点
主节点恢复后,主节点回来变成从机
如果所有某一段插槽的主从节点都宕掉,Redis 服务是否还能继续, 要根据不同的配置而言
redis.conf中配置项:
cluster-require-full-coverage该选项为yes代表整个集群都会挂掉
该选项为no代表只是该插槽数据不能使用也不能存储
5、Jedis开发
pom.xml
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
public class JedisClusterUse {
public static void main(String[] args) {
Set<HostAndPort> set = new HashSet<>();
/*
* set集合可以加入多个地址
* 如果使用集群需要的打开相关的端口防火墙
*/
set.add(new HostAndPort("192.168.50.132", 6379));
// 可以传入set集合,也可单独传入一个地址HostAndPort
JedisCluster jedisCluster = new JedisCluster(set);
jedisCluster.set("address", "beijing");
String address = jedisCluster.get("address");
System.out.println("address=" + address);
}
}
六、集群优缺点
1、优点
- 实现扩容
- 分摊压力
- 无中心配置相对简单
2、缺点
多键操作是不被支持的
多键的 Redis 事务是不被支持的。
lua脚本有限制,使用的 key 必须在同一个槽位,为了保持事务,同一个lua脚本访问应该访问同一个slot,但是redis集群会根据KEY进行hash并取模,因此如果采用默认hash的话,就会出现
command keys must in same slot错误解决方案: redis支持写法,可以实现对KEY的部分字符串进行hash,这样就能保证同一个lua脚本被同一个slot执行,从而保持事务的一致性。
eg. 三个key {top}_turnover_rate,{top}rank,coin_coin 会按 crc16(top) % 16384 的方式取模
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而其它方案想要迁移 至 redis cluster,需要整体迁移而不是逐步过渡,复杂度较大