hadoop入门
一、Hadoop概述
1.Hadoop是什么?
Hadoop是一个开源的框架,使用Java开发,可编写和运行分布式应用处理大规模数据,是专为离线和大规模数据分析而设计的,支持在单台计算机到几千台计算机之间进行扩展,是一个分布式计算的解决方案
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
Hadoop 在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么 HDFS 就相当于这台计算机的硬盘,而 MapReduce 就是这台计算机的 CPU 控制器
Hadoop2.0生态系统架构图:
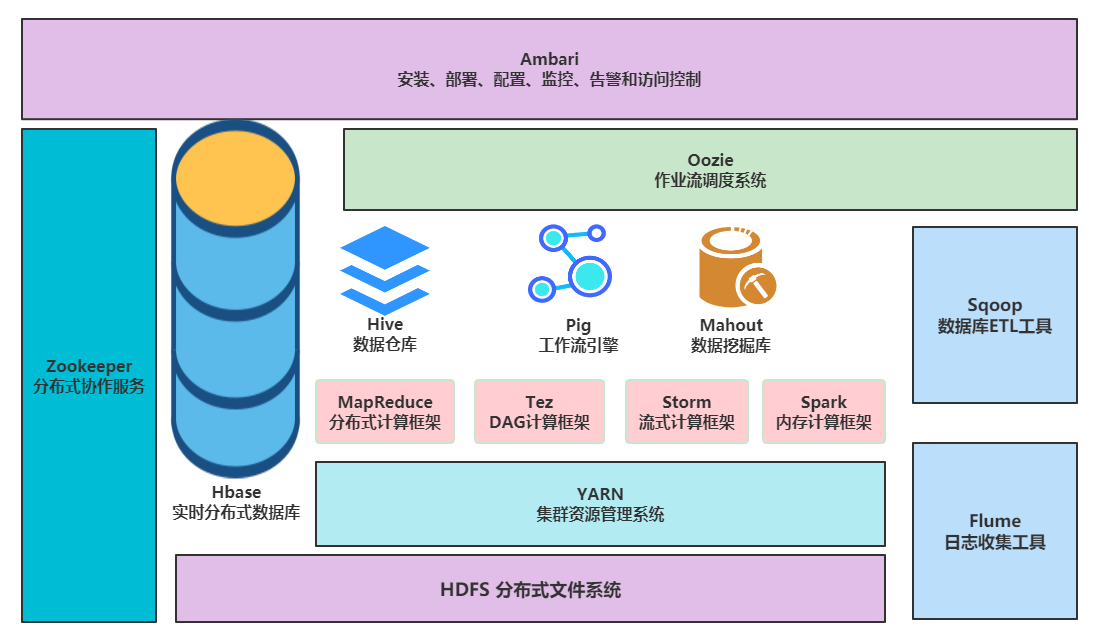
底层:存储层,文件系统HDFS,NoSQL Hbase
中间层:资源及数据管理层,YARN以及Sentry等
上层:MapReduce、Impala、Spark等计算引擎
顶层:基于MapReduce、Spark等计算引擎的高级封装及工具,如Hive、Pig、Mahout
2.使用场景
- 大数据量存储:分布式存储(各种云盘,百度,360~还有云平台均有hadoop应用)
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量读写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目(Apache Mahout简介 常见领域:协作筛选、集群、归类)
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高
- 用户行为特征建模
- 个性化广告推荐
- 智能仪器推荐
3.Hadoop发行版
- Apache Hadoop
- Cloudera’s Distribution Including Apache Hadoop(CDH)
- Hortonworks Data Platform (HDP)
- MapR
- EMR …
Apache Hadoop不足之处:
- 版本管理混乱
- 部署过程繁琐、升级过程复杂
- 兼容性差
- 安全性低
Cloudera版本(CDH)
- 版本划分清晰
- 版本更新速度快
- 支持Kerberos安全认证
- 文档清晰
- 支持多种安装方式(Cloudera Manager方式)
Hortonworks版本(HDP)
区别于其他的Hadoop发行版(如Cloudera)的根本就在于,Hortonworks的产品均是百分之百开源
TDH(Transwarp Data Hub)
TranswarpInceptor是星环科技推出的用于 <font color=red>数据仓库和交互式分析 </font>的大数据平台软件,它基于Hadoop和Spark技术平台打造,加上自主开发的创新功能组件,有效的解决了企业级大数据数据处理和分析的各种技术难题,帮助企业快速的构建和推广数据业务。从2016年起,TDH正式成为Gartner认可的Hadoop国际主流发行版本
4.Hadoop三种运行模式
独立(本地)/单机运行模式:
无需任何守护进程,所有的程序都运行在同一个JVM上执行。在独立模式下调试MR程序非常高效方便。所以一般该模式主要是在学习或者开发阶段调试使用 。
伪分布式模式:
Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的Hadoop集群,单机上的分布式并不是真正的伪分布式,而是使用线程模拟分布式。hadoop本身是无法区分伪分布式和分布式的,两种配置也很相似。
集群/完全分布式模式:
Hadoop守护进程运行在一个集群上,由多个各司其职的节点构成
注:开发环境,使用独立模式;测试环境,可以使用伪分布式模式;线上生产环境,使用完全分布式模式
二、Docker搭建Hadoop环境
软件:Oracle VM VirtualBox Vagrant
操作系统:Centos7
下载地址:
1.搭建Linux平台
vagrant init centos/7 #初始化安装系统信息

vagrant up #下载镜像文件完成安装,会安装ssh工具,默认用户名vagrant
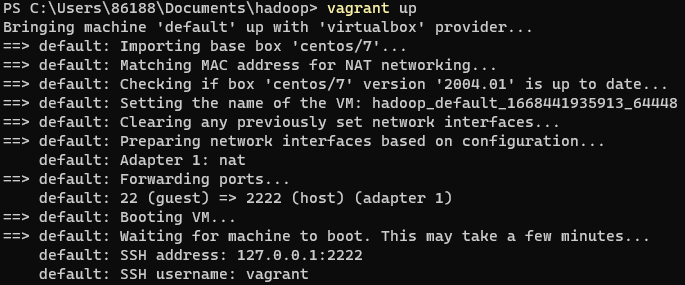
此时打开VirtualBox就可以看到正在运行的虚拟机了
配置网络
编辑vagrantfile使Windows主机与Linux互通
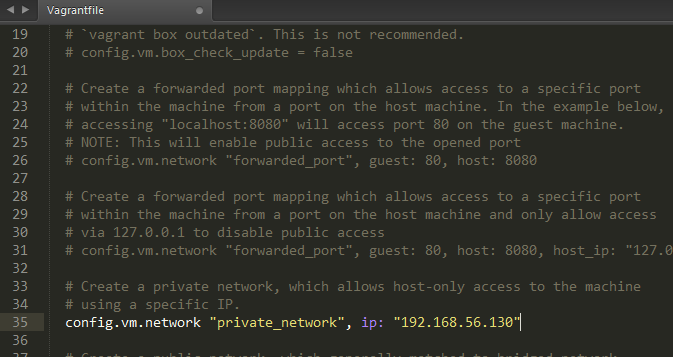
重启Linux系统,使配置生效
vagrant reload #或者vagrant up
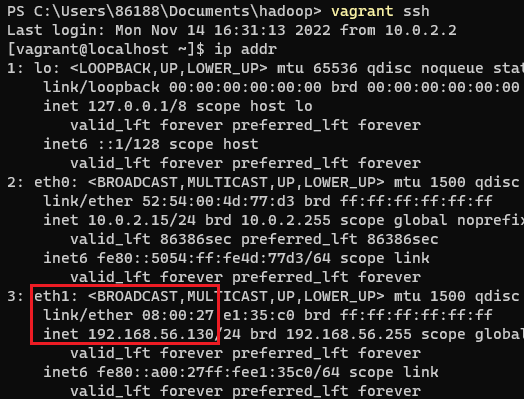
登录Linux系统,查看ip地址
vagrant ssh
ip addr
2.安装docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io
sudo systemctl start docker #启动docker
sudo systemctl enable docker #设置自启动
可自行去阿里云控制台容器服务进行镜像加速配置
3.拉取镜像
sudo docker pull kiwenlau/hadoop:1.0
4.克隆配置脚本
从github上克隆配置脚本,脚本的内容是使用kiwenlau/hadoop:1.0配置mater、slave1、slave2三个容器,其中slave数量可以修改
git clone https://github.com/kiwenlau/hadoop-cluster-docker
如果显示没有git,需要进行安装,sudo yum -y install git
5.创建网桥
由于Hadoop的master节点需要与slave节点通信,需要在各个主机节点配置节点IP,为了不用每次启动都因为IP改变了而重新配置,在此配置一个Hadoop专用的网桥,配置之后各个容器的IP地址就能固定下来
sudo docker network create --driver=bridge hadoop
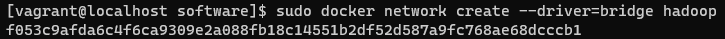
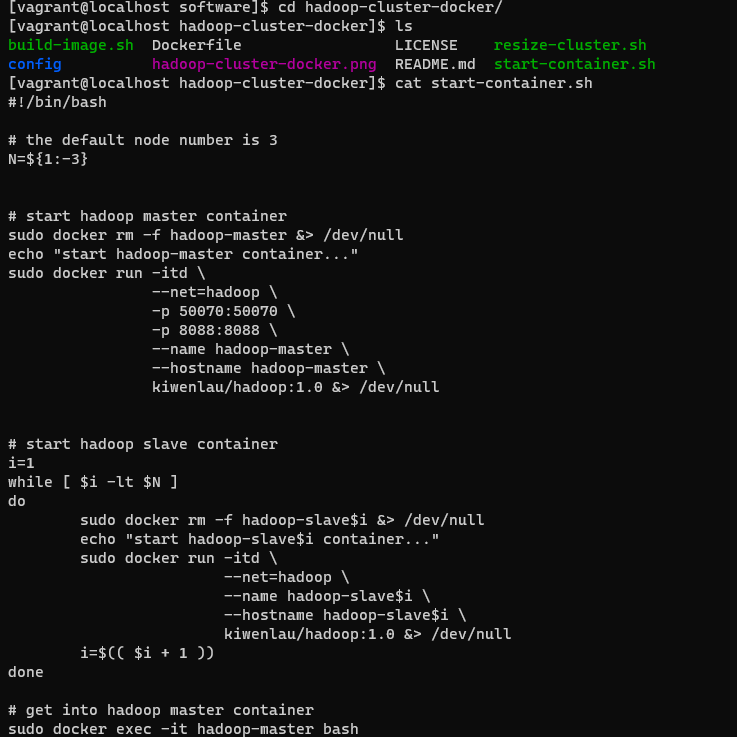
6.执行脚本
通过前面步骤克隆下来的脚本进行容器创建
查看脚本内容:
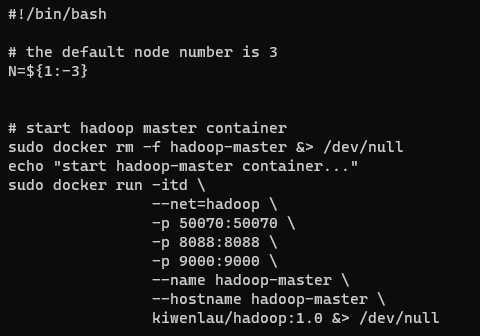
为了后续通过IDEA连接,需要修改脚本,添加一个端口映射,将容器的9000端口映射到本地的9000端口,在-p 8088:8088 \下添加一行如下图所示
执行脚本,脚本在创建完容器之后进入了容器终端

7.安装vim
由于kiwenlau/hadoop:1.0这个镜像没有安装vim编辑器,因此需要先把vim装上
sudo apt-get install vim
8.启动hadoop
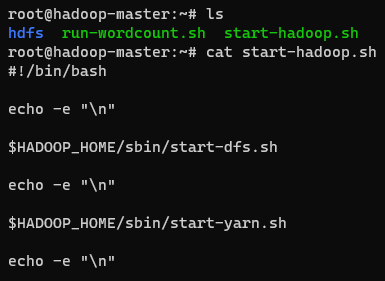
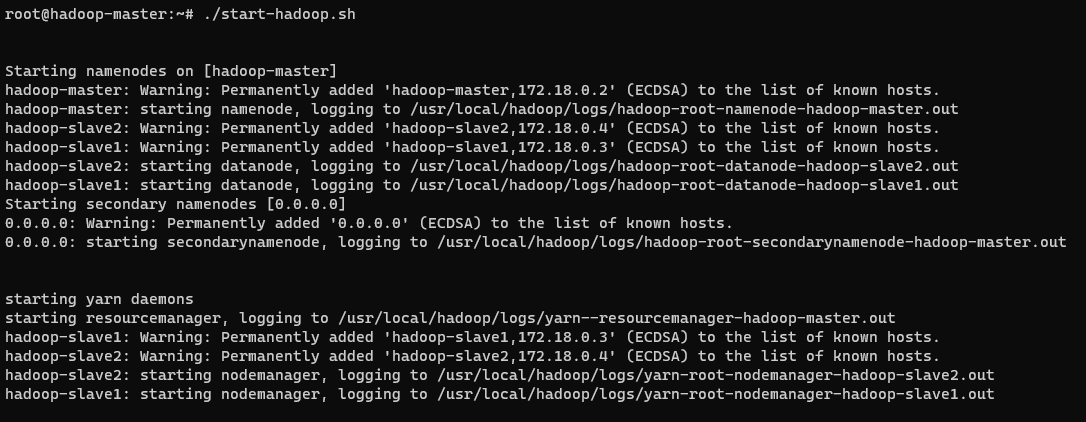
在前面一个步骤的最后进入了Hadoop容器的终端(master节点),因为是已经配置好Hadoop的容器,所以可以直接使用Hadoop,在容器根目录下有一个启动Hadoop的脚本,脚本代码如下,启动了dfs和yarn:
9.测试wordcount
根目录下还有一个测试WordCount程序的脚本,WordCount是Hadoop里“Hello World”程序,是一个用于文本字符统计的MapReduce程序,先来看一下run-wordcount.sh这个脚本的内容,脚本往hdfs里添加了数据文件,然后执行了Hadoop里的例子hadoop-mapreduce-examples-2.7.2-sources.jar: 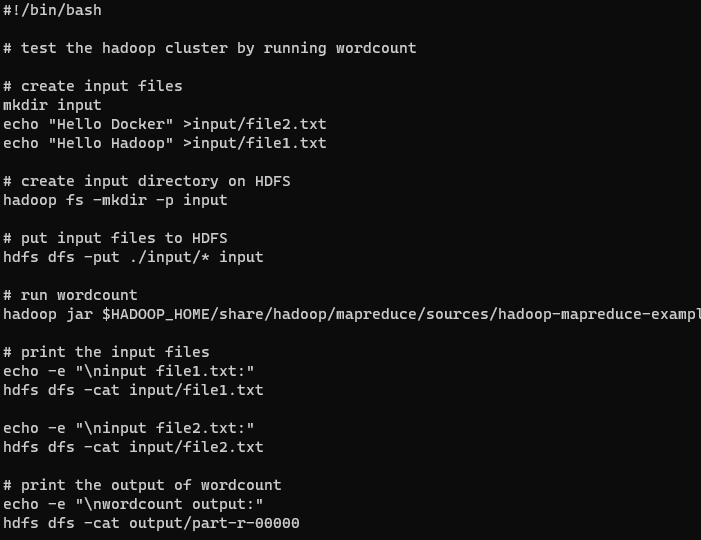
执行脚本:
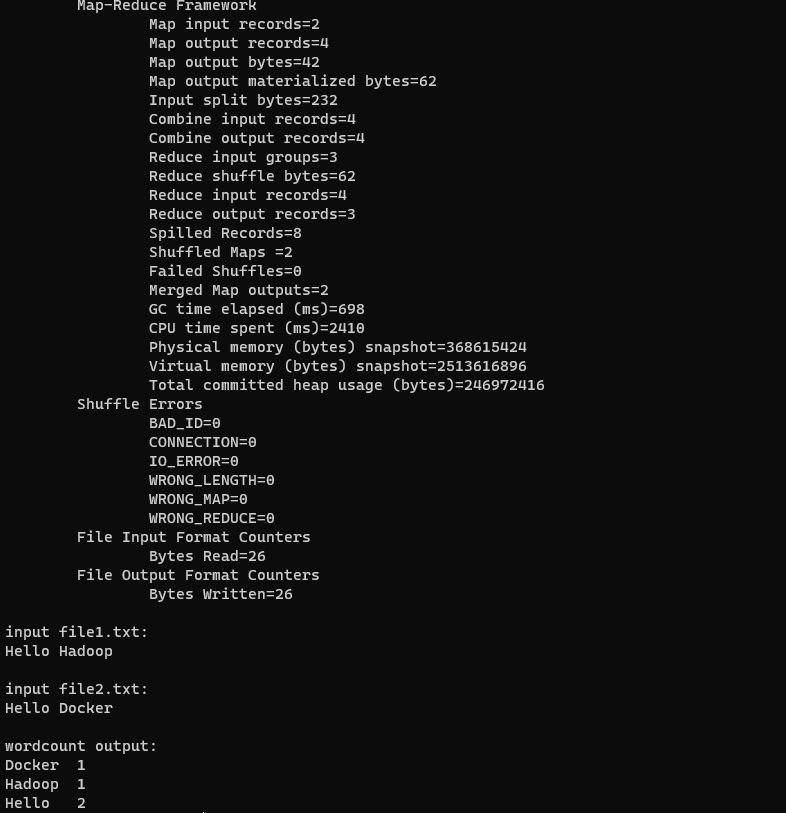
./run-wordcount.sh
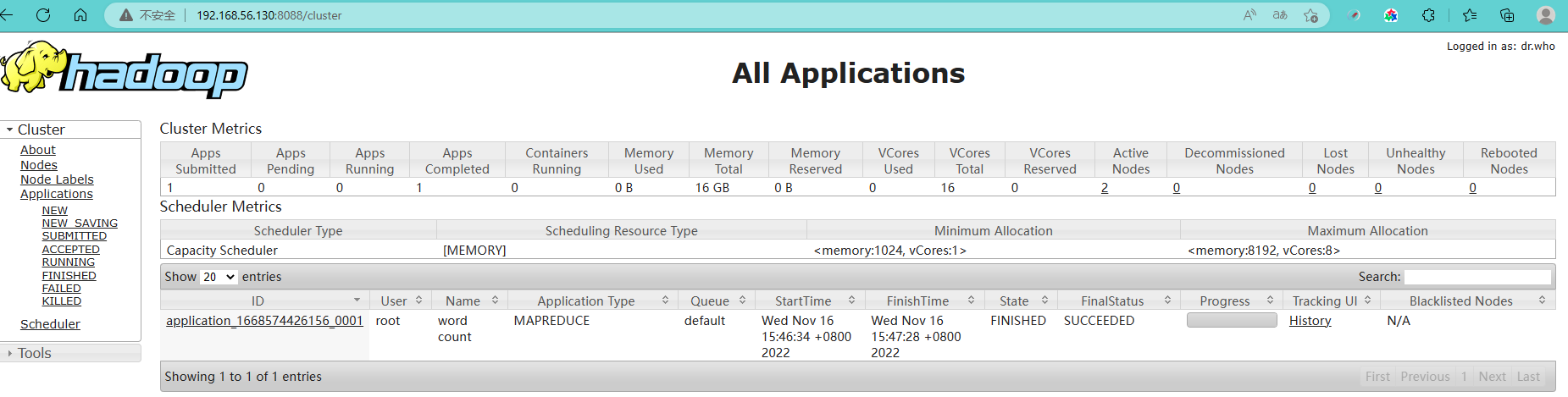
10.查看web页面
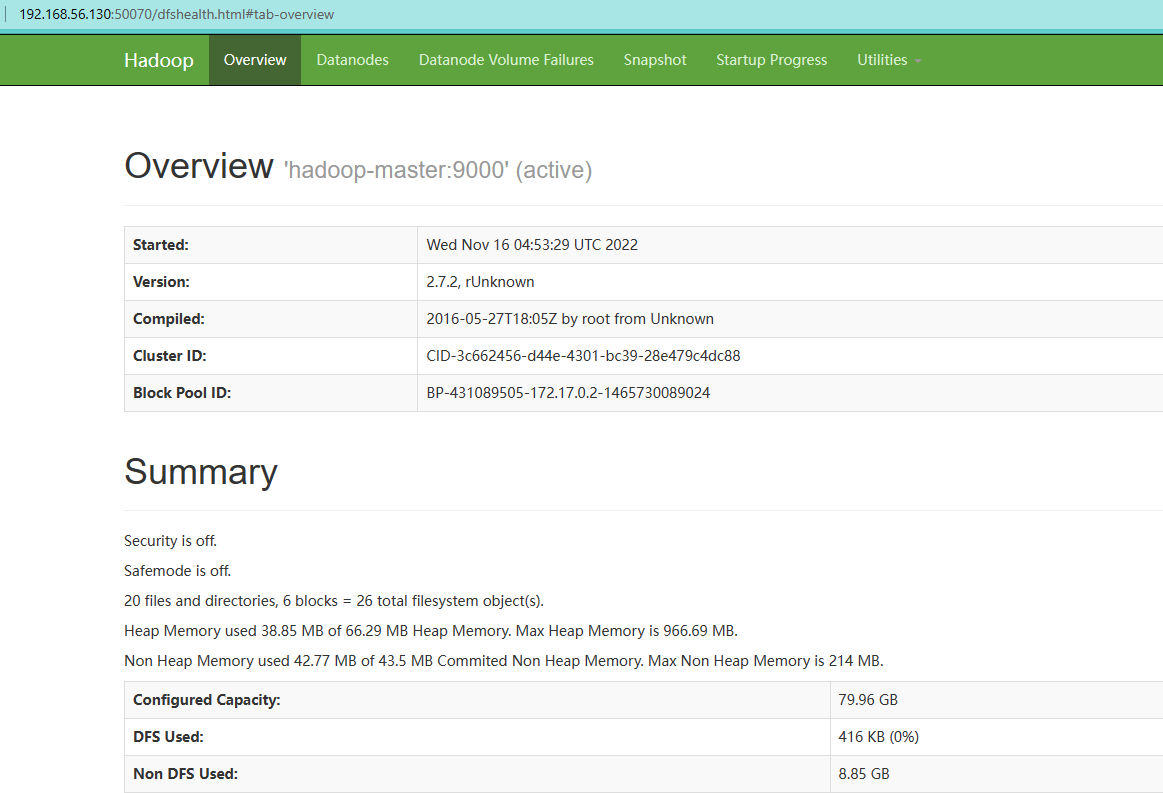
<u>Name Node </u>
打开本地浏览器访问:http://192.168.56.130:50070/ 【这里的ip地址是之前在vagrantfile里面进行配置的】
- 进入页面可以看到各节点的情况,注意如果Summary下的节点信息异常(容量为0、Live Nodes为0等)可能是配置过程出现了问题。
- 在导航栏的Utilities中有两个选项Browse the file system和Logs,前者是查看hdfs文件系统的,后者是查看Hadoop运行日志的,出现任何异常时可以在日志中查看,看能否找出异常原因。
<u>Resource Manager </u>
打开本地浏览器访问:http://192.168.56.130:8088/ ,可以查看Hadoop 应用及执行情况